心理療法における効果検証に用いられる方法に関する問題です。
統計における分析法だったり、研究法だったりが選択肢として設定されていますね。
初出の概念もありますが、過去問をしておくことでいくつかの選択肢を除外できますね。
問97 心理療法における効果検証に用いられる方法として、最も適切なものを1つ選べ。
① 主成分分析
② クラスター分析
③ ランダム化比較試験
④ コレスポンデンス分析
⑤ 修正版グラウンデッド・セオリー・アプローチ
解答のポイント
統計手法・研究法に関して把握していること。
選択肢の解説
① 主成分分析
主成分分析を理解するにあたって、まずは因子分析から理解しておきましょう。
心理学では通常、観測されたデータから目に見えない要因(因子)について議論することが多く、それを検討するためによく用いられるものとして因子分析が広く用いられています。
つまり、因子分析とは「きっと世の中に存在するに違いない「データの背後に潜む説明変数(独立変数)」を見つけ出す分析手法」と言えます。
例えば、国語、数学、理科、社会、英語の5教科があるとして、この5教科の背景にある共通因子を見つけるのが「因子分析」になります。
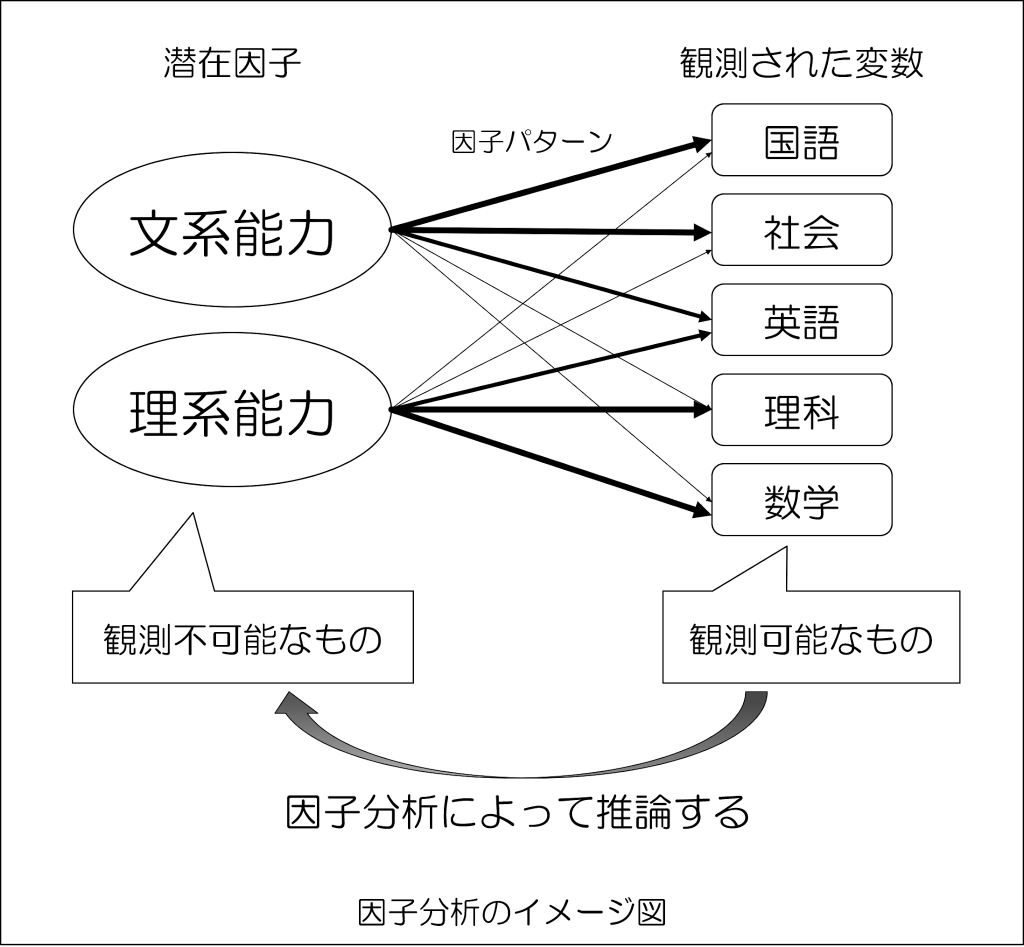
観測された変数である5教科の得点は、共通(潜在)因子(文系能力・理系能力)から影響を受けていることになり、上記の矢印の太さが影響の度合いである「因子負荷量」の大小を表現していると考えてください。
これに対して、主成分分析では「情報を集約すること」が目的になります。
主成分分析では、もともとのデータ(観測された変数)に存在する情報を、新たな軸(成分)で記述するための数学的手法です。
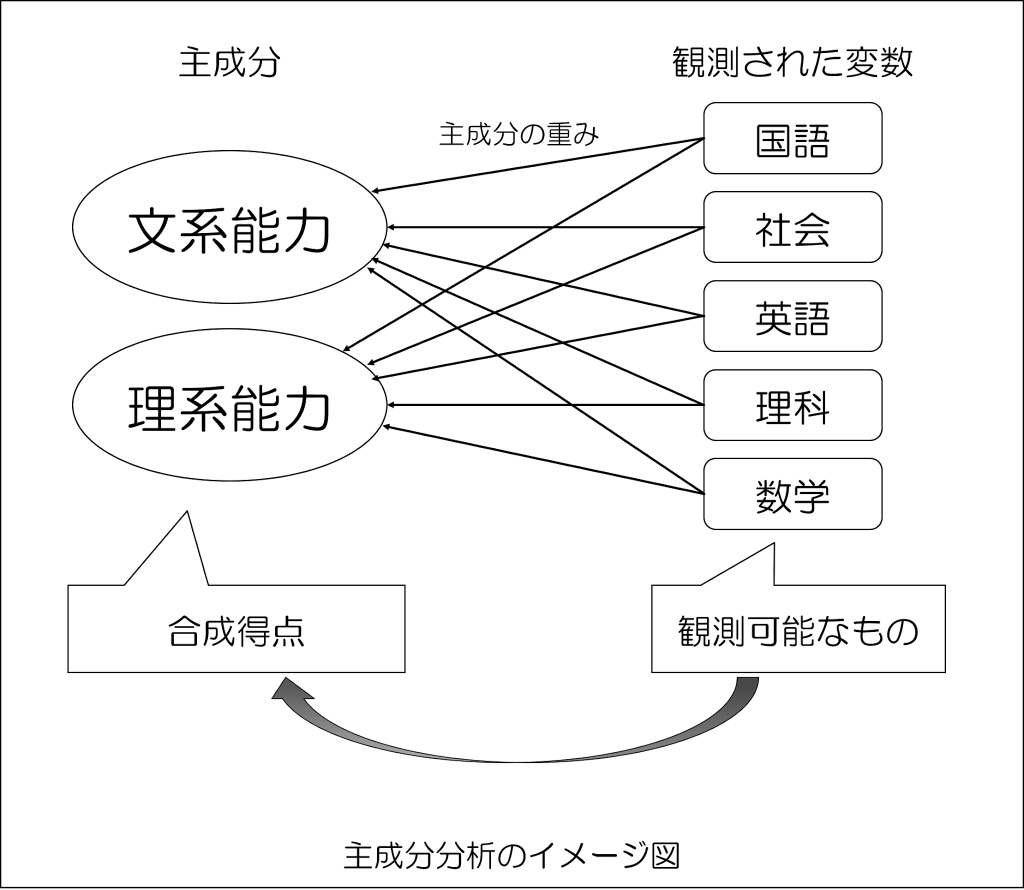
上記のように、潜在因子からの影響を考える「因子分析」とは異なり、「主成分分析」では観測された変数が共有する情報を合成変数として集約するので、図の矢印の向きが逆になっていることがわかりますね。
こうした「主成分分析」の特性上、手元にある多次元のデータから何らかのパターンを見つけ出したいとき、つまりデータ駆動で研究を進めたい場合などに、軸の解釈に注意しながら活用すると有効な方法となります。
もう少しかみ砕いて述べると、主成分分析を用いるのは主として「合成得点を算出したいとき」になります。
例えば、5教科のテスト結果が分かっているとき、5教科の得点を合計して総合得点を算出しますね。
ですが、国語の平均点が20点、数学の平均点が70点だった場合、数学が得意な生徒が総合得点で上位を占めることになってしまい、不公平な結果となります。
このようなときには主成分分析を用いて、各教科の点数に「重みづけをして」をすることで合成得点を算出すると、より実力に応じた結果が見えやすくなります。
つまり、主成分を算出する(主成分=重みつき合計得点)ことで、それぞれの個体の持っている力や特性を識別しやすくすることができるということになりますね。
このように、主成分分析は「相関のある多数の変数から相関のない少数で全体のばらつきを最もよく表す主成分と呼ばれる変数を合成する手法」「たくさんの量的な説明変数を、より少ない指標や合成変数(複数の変数が合体したもの)に要約する手法」であると言えます。
このように捉えてみると、本問で問われている「心理療法における効果検証に用いられる方法」には適さないことがわかると思います。
心理療法を構成しているのは「たくさんの量的な変数」であると見なすのは適切ではないと個人的に思いますし(適切だと言いたい人もいるでしょうけど、この手の議論は着地しないのでしないことにしています)、そもそも「効果検証」ですから主成分分析のような「多くの変数を合成して要約する」というやり方は不適合でしょう。
よって、選択肢①は不適切と判断できます。
② クラスター分析
判別すべき群があらかじめ与えられていない場合に、群を構成する手法、すなわち似た個体同士は同一群、隔たる個体同士は異なる群に属するように個体を群分けする手法を「クラスター分析」と呼びます。
クラスター(cluster)とは、英語で「房」「集団」「群れ」のことで、似たものがたくさん集まっている様子を表し、それが転じて、様々な特性をもつ対象を類似性の指標を元にグルーピングする手法ということになるわけです(この「類似性」というのがクラスター分析のキーワードかなと思います)。
例えば、世界各国の100個のチョコレートを試食したときに「どのくらい甘いか」「どのくらい苦いか」を0~100で評価して、ビジュアルアナログスケールで尋ねたとします。
その結果として、以下のようなデータが得られたとします。
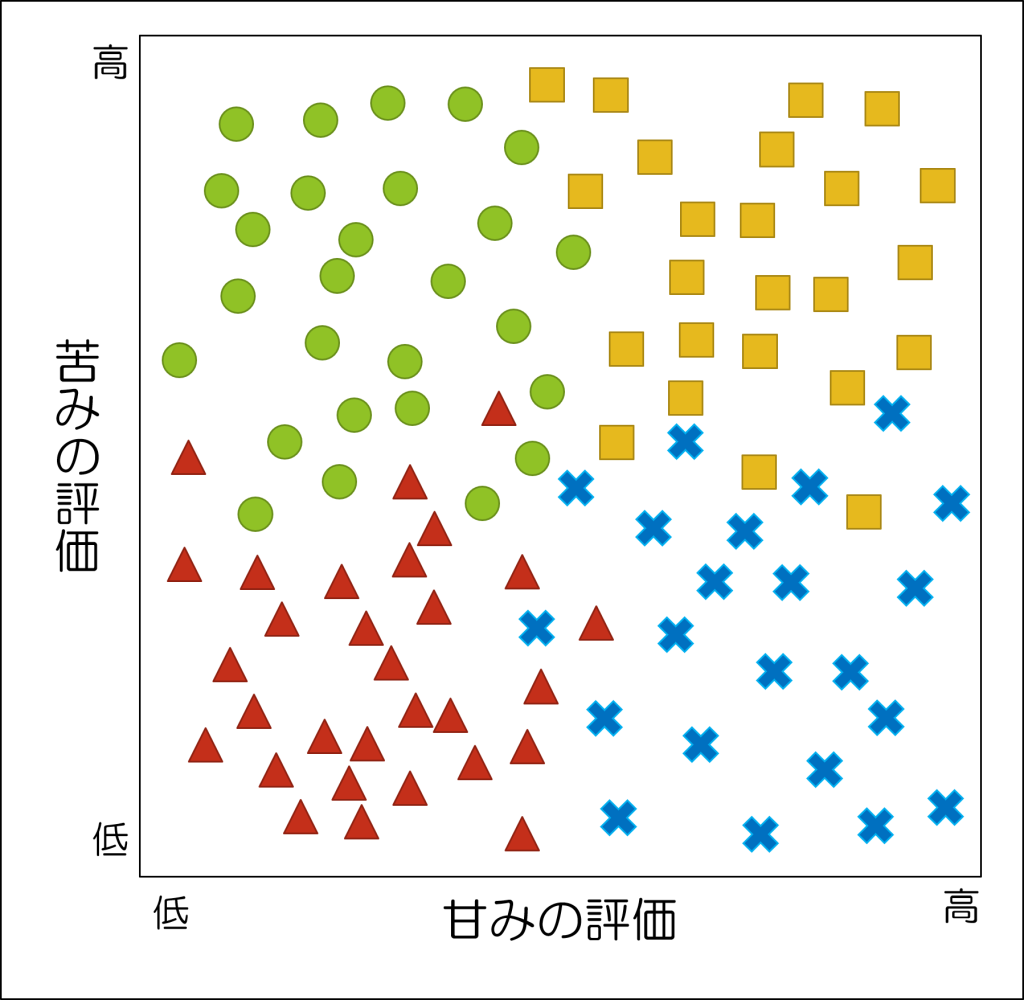
このようにしてみてみると、「甘味も苦みも強いチョコ」「甘味が強いチョコ」「苦みが強いチョコ」「甘味も苦みも弱いチョコ」という4つのまとまりに分かれているように見えますね。
このような時、「類似性」を基準として統計的に対象を分類していくクラスター分析を用いて、まとまりについての検証を行うことができます。
このようにクラスター分析は「判別すべき群があらかじめ与えられていない場合に、群を構成する手法、すなわち似た個体同士は同一群、隔たる個体同士は異なる群に属するように個体を群分けする手法」ですから、本問で問われている「心理療法における効果検証に用いられる方法」には適さないことがわかると思います。
行われている心理療法を群分けしても、心理療法の効果検証にはなりませんからね。
それにクラスター分析は量的変数を用いるので、それも含めて心理療法の効果検証に用いるということは無いだろうと考えられますね(量的変数だからあり得ないとは言えないけど、やはり心理療法の効果というと適しにくいイメージはありますね)。
以上より、選択肢③は不適切と判断できます。
③ ランダム化比較試験
臨床研究では、治療群(治療を行う群、新しいアプローチを実施する群)と対照群(治療をせず観察のみの群 もしくは 従来の介入を行う群)の2つに分けて比較するが、2つの群に分ける際に無作為(=random)に分けている研究を指します。
ランダム化比較試験(Randomized Controlled Trial:RCT)という名の通り、対象者をランダムに2グループに分け(だから「ランダム化」と呼ぶ)、ある特定の手段の介入法を実施するグループ(介入群)と介入しないグループ(比較対照群)間の比較を行い、効果の分析・推論を行います。
その手法特性から、治療などの介入効果を科学的に分析・推論する手法として知られています。
他の条件の介在を排除するため、グループ分けをランダムに行うこと以外にも、対象者自身にもどちらのグループかわからないようにするなど、厳密性の確保のための条件設定が必要とされています(つまり、研究者自身にもどっちのグループが介入群かわからない。期待の効果などによる影響を排除できる)。
なお、ランダム化を行う際にはコンピュータで乱数を発生させて割り付け表を使用する方法が適切だとされています(くじ引きやサイコロの使用、受付番号などでの割り付けは準ランダム化となってしまい真の意味でのランダム化とは言えない)。
その他、コスト面、倫理面の問題もあるが、RCTが実施できれば介入による効果をわかりやすく示せるメリットは大きいです。
このように、ランダム化比較試験が「心理療法における効果検証に用いられる方法」として適切であることがわかりますね。
ある特定の心理療法の効果を検証する場合、「特定の心理療法を実施する群」と「通常の心理療法を実施する群」にランダムに分けて検証するわけです(通常の心理療法ってなんやねん?と思いますけど、そこは置いといて)。
以上より、選択肢③が適切と判断できます。
④ コレスポンデンス分析
コレスポンデンス分析は多変量解析の1つで、クロス表を元に2変量の関係をマッピングする手法です。
コレスポンデンス分析はパリ第6大学のジャン=ポール・ベンゼクリ氏によって開発された分析手法ですが、その根本の考え方やアルゴリズムは林知己夫によって開発された日本独自の多次元データ解析手法である数量化Ⅲ類と同じものとされています。
数量化理論とは林知己夫が開発した質的データの多変量解析であり、「林の数量化理論」などとも呼ばれ、Ⅰ類からⅣ類の4種類あり、そのうちⅠ類~Ⅲ類までが一般に使用されることが多いです。
数量化理論にはそれぞれ類似した方法があり、Ⅰ類は重回帰分析、Ⅱ類は判別分析とそれぞれ類似しておりますが、違いとしては、数量化理論やコレスポンデンス分析は質的変数であり、それぞれの類似した方法は量的変数を扱うことになります。
行の要素と列の要素を使って数量化するとするという点で、コレスポンデンス分析と数量化Ⅲ類は基本的に同じなのですが、数量化理論の場合は集計前のオリジナルデータから処理していくのに対し、コレスポンデンス分析は集計済みのデータを利用する点が異なりますね。
数量化理論Ⅲ類は数多くある観察変数からいくつかの潜在変数を見出す手法で、その潜在変数における各サンプルの得点から、各サンプルの類似度を調べます。
潜在変数を見出す関係式における観察変数のウエイトを用い、観察変数の類似度を調べます。
もともとは缶詰ラベルのデザインを創造する現場から考案されたのが数量化理論Ⅲ類で、「輸出用の缶詰ラベルに富士山や芸者がついていないと重役は承知しない。そういう人は趣味が悪いのだと示したい」というデザイナーの要求に林が応えた形で創案されました。
さまざまなデザインを作り、いろいろな人々に、好きなデザインを選ばせた調査データから目的を達成する解析手法を考案したわけです(人とラベルの相関係数が最大になるように、人とラベルに数量を与えれば、人とラベルをその数量で同時に並び替えたときに対角線上に集まる。趣味のよい人は趣味のよいラベルに、そうでない人はそうでないラベルに集まるパターンを構成できた)。
数量化理論Ⅲ類と同様に、コレスポンデンス(Correspondence)分析は、クロス集計表を可視化して、調査結果の解釈を容易にする分析手法です。
調査データはクロス集計することが多いため、コレスポンデンス分析は非常に利用頻度の高い手法となります。
数量化理論Ⅲ類であれコレスポンデンス分析であれ、計算結果は2軸あるいは3軸のマップ(散布図)で表現されます。
マップ上にプロットした点同士の距離を見ることによって、関係の強弱を感覚的に把握することができるのがこれらの分析法の利点と言えるでしょう。
このページを参照にしてみましょう(会社での昼食と年代のアンケート結果を、コレスポンデンス分析で表現したものになります)。
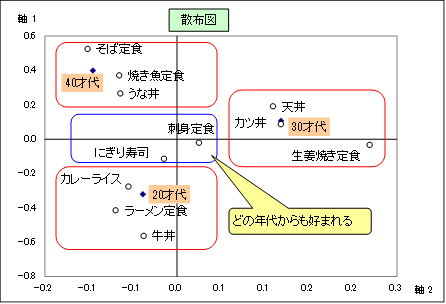
回答のされ方が近いカテゴリー近い位置に存在するので、各年代の周辺に位置する昼食を見て、どの年代がどの昼食を好むか直感的にわかりますね。
細かい分析法に関しては色々ありますが、コレスポンデンス分析や数量化理論Ⅲ類(というか数量化理論)の大きな特徴が、クロス表を元に2変量の関係をマッピングすることで、直感的・感覚的な理解がしやすいという点にあります。
このようにコレスポンデンス分析にはそれ特有の価値があるわけですが、本問で問われている「心理療法における効果検証に用いられる方法」としては不適格であることがわかると思います。
心理療法の効果をマッピングするということは工夫してできたとしても、それによって効果検証になるとは言い難いだろうと考えられますね。
よって、選択肢④は不適切と判断できます。
⑤ 修正版グラウンデッド・セオリー・アプローチ
修正版グラウンデッド・セオリー・アプローチに関しては、昔かなり調べた覚えがあります。
その時には以下の書籍が役立ちました。
引っ越しに伴ってかなりの書籍を処分した際、もう研究はしないだろう、何かの間違いですることになっても、またその時買えばいいや、と思って手放しました。
古い記憶を引っ張り出しながら解説していきましょう。
まずは「修正版」の前に、グラウンデッド・セオリー・アプローチについて説明していきましょう。
これはアメリカの社会学者グレイザーとストラウスによって提唱された、データに根差した理論を算出する質的研究法の一つです。
研究者により様々な方法があるが、標準的な手法は以下の通りです。
- 質的データを区切ってラベルを付ける:コード化
- 似たラベルをまとめてカテゴリーを作る:オープン・コーディング
- カテゴリー同士の関連性を説明して組織化する:アクシャル・コーディング
- アクシャル・コーディングでつくった現象を集め、カテゴリー同士を関係づける。これが、社会現象を説明する理論となる:セレクティブ・コーディング
非常に簡単に書いていますが、特に「修正版」ではない方のグラウンデッド・セオリー・アプローチでは、上記の1が大変でした。
1の内情としては「分析したいものをよく読み十分に理解し、観察結果やインタビュー結果などを文字にして文章(テキスト、データ)を作る」「データへの個人的な思い入れなどは排除し、できるだけ客観的に、文章を細かく分断する(切片化)」「分断した後の文章の、各部分のみを読み、内容を適切に表現する簡潔なラベル(あるいは数字、コード)をつける(このラベルは、抽象度が低い、なるべく具体的な概念名とする)」といったことを行います。
文字起こしをして、それをざっと印刷して切って貼って、これ似てる・同じ感じがする、という感じで集めて…などをしていくわけですね。
こうしてカテゴリーができ、カテゴリー同士の関連性を説明し、その現象を集めることで、起こっていることを「理論」として提出することになります。
ここまでをまとめ、グラウンデッド・セオリー・アプローチの特徴を以下に示します。
- データに密着した分析から独自の説明概念を作って、それらによって統合的に構成された説明力に優れた理論である
- 継続的比較分析法による質的データを用いた研究で生成された理論である。
- 人間と人間の直接的なやり取り、すなわち社会的相互作用に関係し、人間行動の説明と予測に有効であって、同時に、研究者によってその意義が明確に確認されている研究テーマによって限定された範囲内における説明力の優れた理論である。
- 人間の行動、なかんずく他者との相互作用の変化を説明できる、言わば動態的説明理論である。
- 実践的活用を促す理論である。
このようにグラウンデッド・セオリー・アプローチとは、目の前にある現象を「理論」として仕上げていくための研究法であり、生き生きとした「動き」のある現象を表現するものであると言えます。
さて、こうしたグラウンデッド・セオリー・アプローチですが、日本で生まれた木下康仁による修正版があり、理論化の考え方や方法が異なります。
木下は、①データに密着した分析から独自の理論を生成する質的研究法、②コーディング方法としてオープン・コーディングと選択的コーディング、③基軸となる継続的比較分析、④その機能面である理論的サンプリング、⑤分析終了の判断基準としての理論的飽和化、をグラウンデッド・セオリー・アプローチ全体に不可欠なものとして修正版でも採用しています。
修正版グラウンデッド・セオリー・アプローチでは、データの切片化(データを文脈から一旦切り離して、バイアスを軽減するための方法。実際にやるとこれがとても大変な作業になる)を明確に否定しています。
他にも「データに密着した分析をするためのコーディング法を独自に開発(概念を分析の最小単位とするなど)」「研究する人間の視点を重視」「面接型調査に有効に活用できる」「分析作業を段階分けせずに、解釈の多重的同時並行性を特徴とする」などの修正点があります。
上記を読んでも、やはりグラウンデッド・セオリー・アプローチにせよ修正版にせよ、イメージが湧きにくいと思います。
これらはやってみれば「そういうやり方なのね」と理解しやすいのですが、自転車の運転と同じで言葉にするとやけに難しくなってしまいます。
ただ、いずれにせよ「グラウンデッド・セオリー・アプローチ」と「修正版グラウンデッド・セオリー・アプローチ」で方法の違いや省く過程はあったりするものの、根っことして「目の前にある現象を「理論」として仕上げていくための研究法」であるという点は共通しているとみてよいです。
さて、そのように考えると、本問で問われている「心理療法における効果検証に用いられる方法」としては不適格であることがわかると思います。
もしかしたら、ある実践家のやり取りを記録し、それをもとに「新しい心理療法的な関わり」や「セラピストとクライエントとの間で生じる現象」を概念化するための方法として、修正版グラウンデッド・セオリー・アプローチは有効かもしれませんが、あくまでも「心理療法における効果検証に用いられる方法」が問われているわけですから、目的と合致しませんね。
以上より、選択肢⑤は不適切と判断できます。
いつもお世話になっております。まず、「心理療法における効果検証」で「③ ランダム化比較試験」という試験機関の考え方がわかりません。無作為なんて実験の基礎だと思います。また、心理療法とは、アイゼンクが考えたように行動療法以外を指すのか、それとも、薬物療法対心理療法なのか、で異なると思います。そして、ある心理療法を受けたか否かでしょうか。薬物療法対心理療法だとすれば、ランダム化比較試験だけでは効果検証ができるのか疑問です。如何でしょうか。