特性論の歴史的背景に関する問題です。
統計手法が選択肢で述べられていますが、統計に関する問題ではありません。
なので統計に関する説明は軽くにしておきました。
問80 G.W.AllportやR.B.Cattellらの特性論の考えを引き継ぎ、L.R.Goldbergが指摘した性格特性理論の基盤となっている統計手法として、適切なものを1つ選べ。
① 因子分析
② 分散分析
③ 共分散分析
④ 重回帰分析
⑤ クラスター分析
関連する過去問
解答のポイント
特性論研究の歴史的背景を理解している。
選択肢の解説
① 因子分析
Allportは特性論の代表的研究者であり、彼の特性論を時系列に学ぶときに押さえておかねばならないのが、「Goldbergの基本辞書仮説」です。
基本辞書仮説(=重要な特性は必ず自然言語に符号化されているはず)に基づいて、特性語を網羅的に収集し、それを分類整理することによって、基本的な特性や構造を明らかにしようとする「語彙アプローチ」を実践しました。
Allportは辞書に掲載されている性格表現用語として約18000語を抽出した上で、これを整理・分類し、4504語を主要な性格表現用語としてまとめました。
しかし、これを適切に処理する方法が見つからず、長く放置されることになります。
ここから2つの流れで説明していくことにしましょう。
まず1つの流れとして、Cattellは、Allportの意図を更に推し進めて、因子分析を用いてパーソナリティ構造を明らかにしようとしました。
彼はAllportと同様に、類似の社会経験をしている全ての人に共通の「共通特性」と、特定個人に特有の「独自特性」に分けました。
そして「独自特性」は、以下の二つに分けられると考えました。
- 表面特性:外部から観察可能な、互いに相関し合っているクラスター。
- 根源特性:表面特性を因子分析して見出された、表面のさらに根底にある特性。
彼は少なくとも25個の根源特性を見出しており、そのうち16因子を測定するために標準化されたのが16因子パーソナリティ因子質問紙(16PF)になります。
もう1つの流れとして、Allportが集めはしましたが手つかずになっていた特性語のまとまりに対し因子分析研究が盛んに行われ、5因子が共通して見出されるようになりました。
Goldbergはこの5因子を、以下のように解釈・命名し「Big Five」と呼びました。
- 外向性:対人関係や外界に対する働きかけにおける積極性を示す。
- 調和性:対人関係における共感性や思いやりに関わる。
- 勤勉誠実性:仕事面におけるセルフ・コントロールや責任感に関わる。
- 情緒安定性(神経症傾向):情動における安定性。
- 知性(開放性):知的関心における開放性を示す。
これらは文化差や民族差を超えた普遍性を持つものとして、1990年代からはこの5因子モデルがパーソナリティ研究の中心的位置を占めるようになっていきました。
Costa &McCraeはこの5因子を測定するために、NEO-PI-R(Revised NEO Personality Inventory)を開発しています。
上記の通り、本問の「G.W.AllportやR.B.Cattellらの特性論の考えを引き継ぎ、L.R.Goldbergが指摘した性格特性理論の基盤となっている統計手法」とは因子分析であることがわかりますね。
よって、選択肢①が適切と判断できます。
② 分散分析
③ 共分散分析
上記の通り、すでに本問の解答は因子分析となっておりますが、ここでは本選択肢の分散分析について簡単に述べておきます。
分散分析は「分散」すなわちバラつきをバラして分析する手法です。
分散分析ではバラつきを以下のように分けます。
- 全体平方和:データ全体のバラつき
- 群間平方和:平均値の違いで説明できるバラつき
- 郡内平方和:平均値の違いでは説明できないバラつき
これだけでは分かりづらいと思うので、過去に作った資料の一部を示します。
こちらは睡眠薬と偽薬、その睡眠量を例にとったので、そういうことが書いてあります。

この中でどこを見ればよいのかを知っておくことが大切です。
当然ですが「群の違いによって説明できるバラつき」>「誤差によって生じるバラつき」である必要があるので、この2つを比較検討を行っていくわけです。
この比較検討の結果、F値(統計量F)が算出されます。
一般にF値とは、2つの群の標準偏差の比であって、両群とも正規分布に従う場合にはF値はF分布に従うことになります。F分布表とは以下のようなものになります(有意確率5%のみ示しています)。
算出されたF値が、所定の数字を超えていたならば「有意である(5%水準で)」と言えるわけです。
非常に簡単に述べていますが、「公認心理師 2019-80」の中で詳しく解説してあるので、気になる方はこちらをどうぞ。
なお、共分散分析は、平均値に影響を及ぼすデータ(共変量)があった時に、その共変量の影響を取り除いて群間を比較することができる解析手法ですから、分散分析と重回帰分析を組み合わせた手法とされています(ですから、基本的に共分散分析は分散分析と同じように「群間比較」を目的として使われる統計手法です)。
分散分析では説明変数に集団などカテゴリー変数(要因)のみを投入しますが、 共分散分析ではカテゴリー変数(要因)と連続変数(共変量)の両方を投入するのが特徴です。
以上より、選択肢②および選択肢③は不適切と判断できます。
④ 重回帰分析
上記の通り、すでに本問の解答は因子分析となっておりますが、ここでは本選択肢の重回帰分析について簡単に述べておきます。
重回帰分析とは、従属変数のばらつきを、いくつかの独立変数によって説明したり、予測するための統計的手法のことです。
一つの従属変数に対して、一つの独立変数によって説明・予測するのを「単回帰分析」と呼びます(重回帰分析は独立変数が複数あります)。
例えば、身長を体重という一つの説明変数から予測するのは単回帰分析であるのに対して、重回帰分析は身長を体重、年齢、性別など複数の説明変数から予測します。
まずは単回帰分析のやり方を踏まえて、重回帰分析を理解していきましょう。
例えば、身長と体重の以下のような表があるとしましょう。

この時、Aさん~Eさんの身長体重がわかっているので、そこからFさんの身長を予測しようとします。
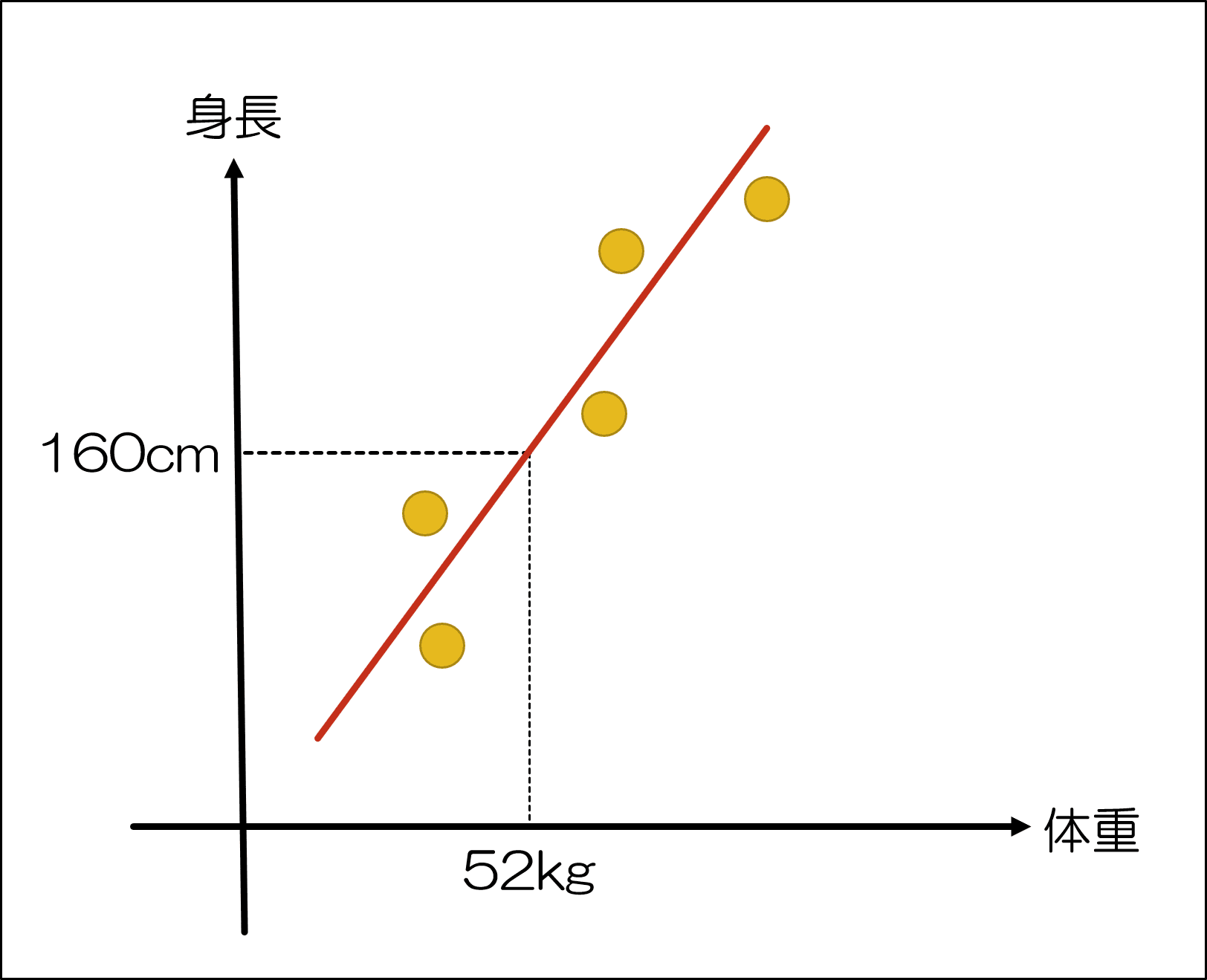
その結果、上記のような赤線を引くことができましたので、そこから「体重52kg」は「身長160cm」であると推測することができますね。
これを「y=ax+b」と表現します。
yは従属変数(身長)であり、xは独立変数(体重)、aは傾きで定数が入り、bは切片で同じく定数が入ります。
こうした直線を描くことができれば、2変数間の関係を表現できていることになり、仮説が統計的に検証されたと考えることができます。
これが単回帰分析の基本的な考え方になります。
重回帰分析では、独立変数が複数になってきます。
例えば、身長という従属変数を、体重と足のサイズという2つの独立変数で予測しようとするときには「y=a1x(体重)+a2x(足のサイズ)+b」となるわけです。
上記の赤線を回帰(重回帰)分析では「回帰」と呼びますが、この回帰モデルの当てはまりの良さ、つまり、得られた回帰式が従属変数の変動をどの程度よく説明しているかは「重相関係数」や「決定係数」を指標として評価することができます。
以上より、選択肢④は不適切と判断できます。
⑤ クラスター分析
上記の通り、すでに本問の解答は因子分析となっておりますが、ここでは本選択肢のクラスター分析について簡単に述べておきます。
判別すべき群があらかじめ与えられていない場合に、群を構成する手法、すなわち似た個体同士は同一群、隔たる個体同士は異なる群に属するように個体を群分けする手法を「クラスター分析」と呼びます。
簡単に言えば、様々な特性をもつ対象を類似性の指標を元にグルーピングする手法ですね(この「類似性」というのがクラスター分析のキーワードかなと思います)。
例えば、世界各国の100個のチョコレートを試食したときに「どのくらい甘いか」「どのくらい苦いか」を0~100で評価して、ビジュアルアナログスケールで尋ねたとします。
その結果として、以下のようなデータが得られたとします。

このようにしてみてみると、「甘味も苦みも強いチョコ」「甘味が強いチョコ」「苦みが強いチョコ」「甘味も苦みも弱いチョコ」という4つのまとまりに分かれているように見えますね。
このような時、「類似性」を基準として統計的に対象を分類していくクラスター分析を用いて、まとまりについての検証を行うことができます。
クラスター分析には大きく分けて、階層的クラスター分析と非階層的クラスター分析があります。
階層的クラスター分析では、個々のデータを1つのクラスターとしてみなし、類似性に基づいてクラスターを結合していき、この手続きを最終的に1つのクラスターが形成されるまで続けます。
一方で、非階層的クラスター分析では、分析者が事前にクラスター数を設定し、データをそのクラスター数に分ける方法です。
以上より、選択肢⑤は不適切と判断できます。